


 企业资料通过认证
企业资料通过认证
2017 年 Google 提出了 Transformer [1] 模型,之后在它基础上诞生了许多优秀的预训练语言模型和机器翻译模型,如 BERT [2] 、GPT 系列[13]等,不断刷新着众多自然语言处理任务的能力水平。与此同时,这些模型的参数量也在呈现近乎指数增长(如下图所示)。例如最近引发热烈讨论的 GPT-3 [3],拥有 1750 亿参数,再次刷新了参数量的记录。
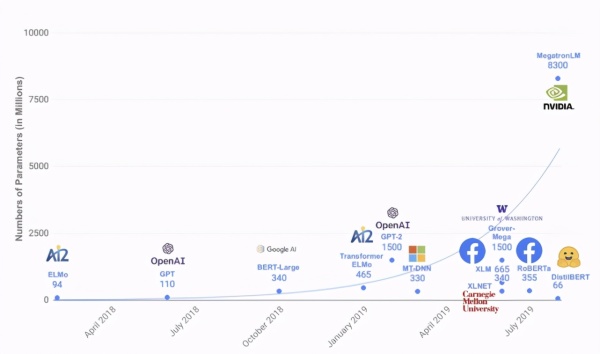
如此巨大的参数量,也为模型推理部署带来了挑战。以机器翻译为例,目前 WMT[4]比赛中 SOTA 模型已经达到了 50 层以上。主流深度学习框架下,翻译一句话需要好几秒。这带来了两个问题:一是翻译时间太长,【企闻】一种基于硬质合金的铰刀的制作方法,影响产品用户体验;二是单卡 QPS (每秒查询率)太低,导致服务成本过高。
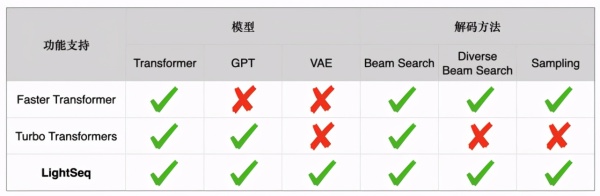
因此,今天给大家安利一款速度非常快,同时支持非常多特性的高性能序列推理引擎——LightSeq。它对以 Transformer 为基础的序列特征提取器(Encoder)和自回归的序列解码器(Decoder)做了深度优化,早在 2019 年 12 月就已经开源,应用在了包括火山翻译等众多业务和场景。据了解,这应该是业界第一款完整支持 Transformer、GPT 等多种模型高速推理的开源引擎。
LightSeq 可以应用于机器翻译、自动问答、智能写作、对话回复生成等众多文本生成场景,大大提高线上模型推理速度,改善用户的使用体验,降低企业的运营服务成本。
LightSeq推理速度非常快。例如在翻译任务上,LightSeq相比于Tensorflow实现最多可以达到14倍的加速。同时领先目前其他开源序列推理引擎,例如最多可比Faster Transformer快1.4倍。
LightSeq通过定义模型协议,支持各种深度学习框架训练好的模型灵活导入。同时包含了开箱即用的端到端模型服务,即在不需要写一行代码的情况下部署高速模型推理,同时也灵活支持多层次复用。
利用 LightSeq 部署线上服务比较简便。LightSeq 支持了 Triton Inference Server[8],这是 Nvidia 开源的一款 GPU 推理 server ,包含众多实用的服务中间件。LightSeq 支持了该 server 的自定义推理引擎 API 。因此只要将训练好的模型导出到 LightSeq 定义的模型协议[9]中,就可以在不写代码的情况下,一键启动端到端的高效模型服务。更改模型配置(例如层数和 embedding 大小)都可以方便支持。具体过程如下:
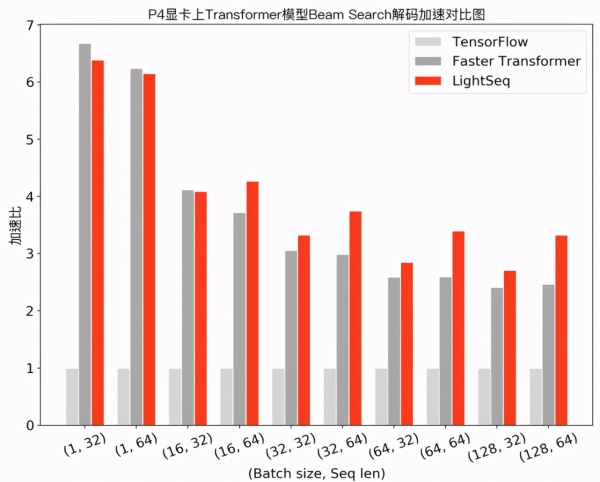
可以发现,在小 batch 场景下,Faster Transformer 和 LightSeq 对比 Tensorflow 都达到了 10 倍左右的加速。而随着 batch 的增大,由于矩阵乘法运算占比越来越高,两者对 Tensorflow 的加速比都呈衰减趋势。LightSeq 衰减相对平缓,特别是在大 batch 场景下更加具有优势,最多能比 Faster Transformer 快 1.4 倍。这也对未来的一些推理优化工作提供了指导:小 batch 场景下,只要做好非计算密集型算子融合,就可以取得很高的加速收益;而大 batch 场景下则需要继续优化计算密集型算子,例如矩阵乘法等。
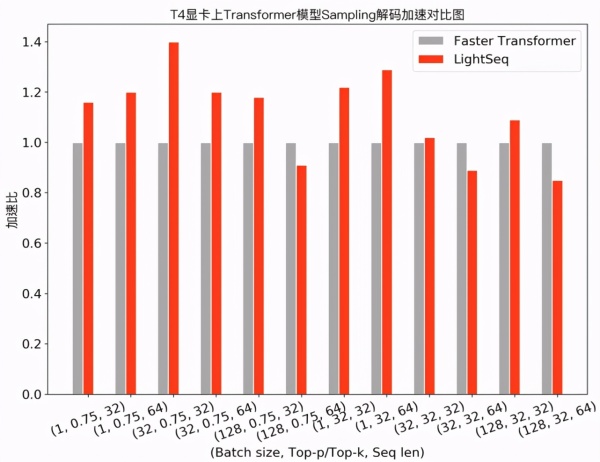
可以发现,在需要使用采样解码的任务中,LightSeq 在大部分配置下领先于 Faster Transformer,最多也能达到 1.4 倍的额外加速。此外,相比于 TensorFlow 实现,LightSeq 对 GPT 和 VAE 等生成模型也达到了 5 倍以上的加速效果。
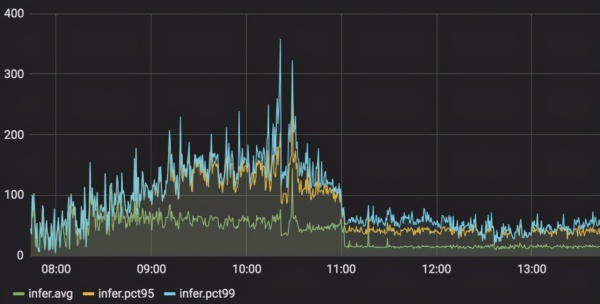
在云服务上,笔者测试了在实际应用中 GPT 场景下,模型服务从 Tensorflow 切换到LightSeq 的延迟变化情况(服务显卡使用 NVIDIA Tesla P4)。可以观察到,pct99 延迟降低了 3 到 5 倍,峰值从 360 毫秒左右下降到 80 毫秒左右,详细结果如下图所示:
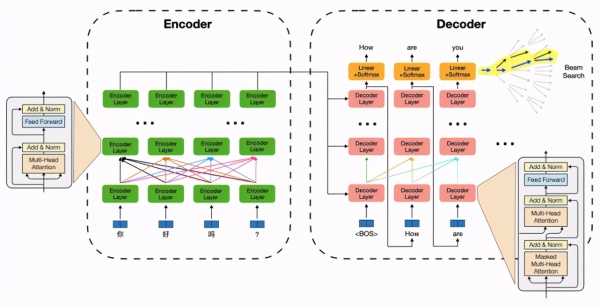
以 Transformer 为例,一个机器翻译/文本生成模型推理过程包括两部分:序列编码模块特征计算和自回归的解码算法。其中特征计算部分以自注意力机制及特征变换为核心(矩阵乘法,计算密集型),并伴随大量 Elementwise(如 Reshape)和 Reduce(如Layer Normalization)等 IO 密集型运算;解码算法部分包含了词表 Softmax、beam 筛选、缓存刷新等过程,运算琐碎,并引入了更复杂的动态 shape。这为模型推理带来了众多挑战:
2. 复杂动态 shape 为计算图优化带来挑战,导致模型推理期间大量显存动态申请,耗时较高。
LightSeq 取得这么好的推理加速效果,对这些挑战做了哪些针对性的优化呢?笔者分析发现,核心技术包括这几项:融合了多个运算操作来减少 IO 开销、复用显存来避免动态申请、解码算法进行层级式改写来提升推理速度。下面详细介绍下各部分的优化挑战和 LightSeq 的解决方法。
近年来,由于其高效的特征提取能力,Transformer encoder/decoder 结构被广泛应用于各种 NLP 任务中,例如海量无标注文本的预训练。而多数深度学习框架(例如 Tensorflow、Pytorch 等)通常都是调用基础运算库中的核函数(kernel function)来实现 encoder/decoder 计算过程。这些核函数往往粒度较细,通常一个组件需要调用多个核函数来实现。
可以发现,即使基于编译优化技术(自动融合广播(Broadcast)操作和按元素(Elementwise)运算),也依然需要进行三次核函数调用(两次 reduce_mean,一次计算最终结果)和两次中间结果的显存读写(mean 和 variance)。深圳市心雨在线科技开发有限公司。而基于 CUDA,我们可以定制化一个层归一化专用的核函数,将两次中间结果的写入寄存器。从而实现一次核函数调用,同时没有中间结果显存读写,因此大大节省了计算开销。有兴趣的同学可以在文末参考链接中进一步查看具体实现[11]。
基于这个思路,LightSeq 利用 CUDA 矩阵运算库 cuBLAS[12]提供的矩阵乘法和自定义核函数实现了 Transformer,具体结构如下图所示:
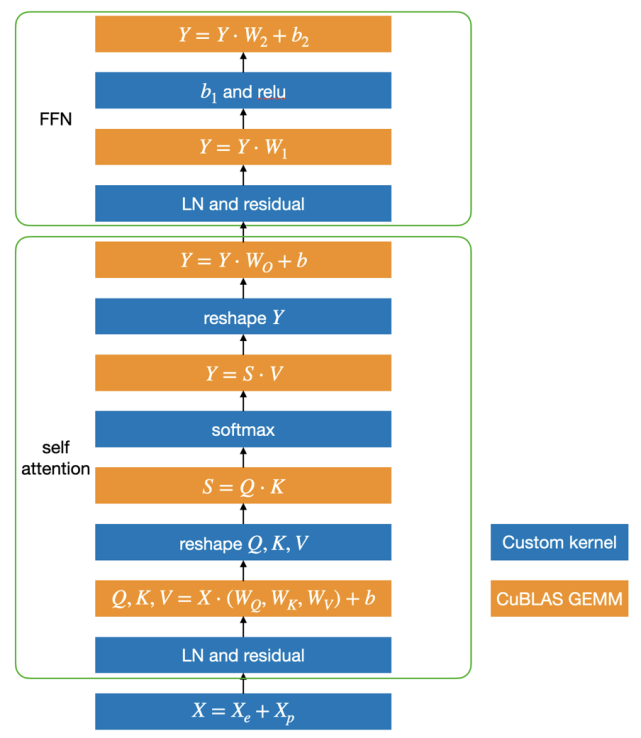
蓝色部分是自定义核函数,黄色部分是矩阵乘法。可以发现,矩阵乘法之间的运算全部都用一个定制化核函数实现了,因此大大减少了核函数调用和显存读写,最终提升了运算速度。
为了避免计算过程中的显存申请释放并节省显存占用,LightSeq 首先对模型中所有动态的 shape 都定义了最大值(例如最大序列长度),将所有动态shape转换为静态。接着在服务启动的时候,为计算过程中的每个中间计算结果按最大值分配显存,并对没有依赖的中间结果共用显存。这样对每个请求,模型推理时不再申请显存,做到了:不同请求的相同 Tensor 复用显存;同请求的不同 Tensor 按 shape 及依赖关系复用显存。
可以发现,为了挑选概率 top-k 的 token ,必须在 [batch_size, beam_size, vocab_size]大小的 logit 矩阵上进行 softmax 计算及显存读写,然后进行 batch_size 次排序。通常 vocab_size 都是在几万规模,因此计算量非常庞大,而且这仅仅只是一步解码的计算消耗。因此实践中也可以发现,解码模块在自回归序列生成任务中,累计延迟占比很高(超过 30%)。
LightSeq 的创新点在于结合 GPU 计算特性,借鉴搜索推荐中常用的粗选-精排的两段式策略,将解码计算改写成层级式,设计了一个 logit 粗选核函数,成功避免了 softmax 的计算及对十几万元素的排序。该粗选核函数遍历 logit 矩阵两次:
• 第一次遍历,对每个 beam,将其 logit 值随机分成k组,每组求最大值,然后对这k个最大值求一个最小值,作为一个近似的top-k值(一定小于等于真实top-k值),记为R-top-k。在遍历过程中,同时可以计算该beam中logit的log_sum_exp值。
在第一次遍历中,logit 值通常服从正态分布,因此算出的R-top-k值非常接近真实top-k值。同时因为这一步只涉及到寄存器的读写,且算法复杂度低,因此可以快速执行完成(十几个指令周期)。实际观察发现,在top-4设置下,根据R-top-k只会从几万token中粗选出十几个候选,因此非常高效。第二次遍历中,根据R-top-k粗选出候选,同时对 logit 值按 batch_id 做了值偏移,多线程并发写入显存中的候选队列。
粗选完成后,在候选队列中进行一次排序,就能得到整个batch中每个序列的准确top-k值,然后更新缓存,一步解码过程就快速执行完成了。
下面是k=2,词表大小=8的情况下一个具体的示例(列代表第几个字符输出,行代表每个位置的候选)。可以看出,原来需要对 16 个元素进行排序,而采用层级解码之后,最后只需要对 5 个元素排序即可,大大降低了排序的复杂度。

为了验证上面几种优化技术的实际效果,笔者用 GPU profile 工具,对 LightSeq 的一次推理过程进行了延迟分析。下图展示了 32 位浮点数和 16 位浮点数精度下,各计算模块的延迟占比:
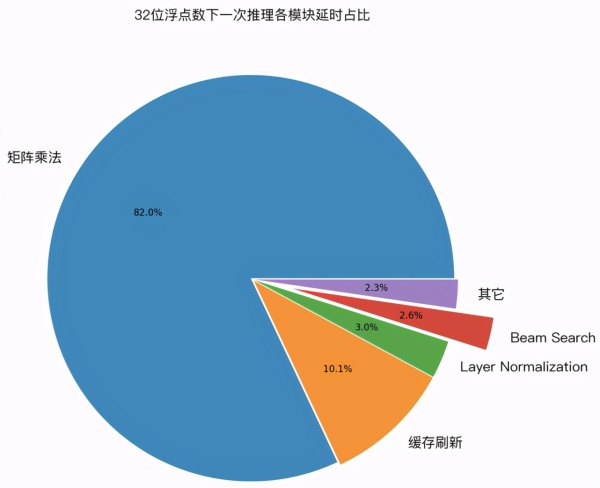
1. 经过优化后,cuBLAS 中的矩阵乘法计算延迟分别占比 82% 和 88% ,成为推理加速新的主要瓶颈。而作为对比,我们测试了 Tensorflow 模型,矩阵乘法计算延迟只占了 25% 。这说明 LightSeq 的 beam search 优化已经将延迟降到了非常低的水平。
2. 缓存刷新分别占比 10% 和 6% ,比重也较高,但很难继续优化。今后可以尝试减少缓存量(如降低 decoder 层数,降低缓存精度等)来继续降低延迟。