人工智能芯片目前有两种发展路径:一种是延续传统计算架构,加速硬件计算能力,主要以 3 种类型的芯片为代表,即依旧发挥着不可替代的作用;另一种是颠覆经典的冯·诺依曼计算架构,采用类脑神经结构来提升计算能力,以IBM TrueNorth 芯片为代表。
计算机工业从1960年代早期开始使用CPU这个术语。迄今为止,CPU从形态、设计到实现都已发生了巨大的变化,但是其基本工作原理却一直没有大的改变。 通常 CPU 由控制器和运算器这两个主要部件组成。 传统的 CPU 内部结构图如图所示:
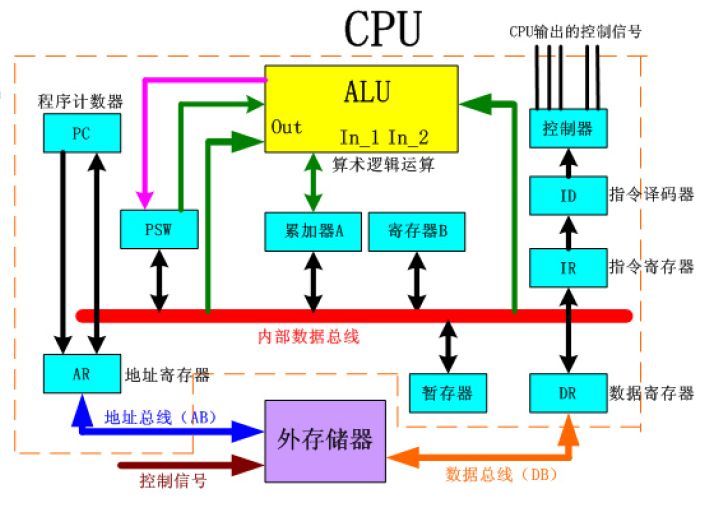
从图中我们可以看到:实质上仅单独的ALU模块(逻辑运算单元)是用来完成数据计算的,其他各个模块的存在都是为了保证指令能够一条接一条的有序执行。这种通用性结构对于传统的编程计算模式非常适合,同时可以通过提升CPU主频(提升单位时间内执行指令的条数)来提升计算速度。 但对于深度学习中的并不需要太多的程序指令、 却需要海量数据运算的计算需求, 这种结构就显得有些力不从心。尤其是在功耗限制下, 无法通过无限制的提升 CPU 和内存的工作频率来加快指令执行速度, 这种情况导致 CPU 系统的发展遇到不可逾越的瓶颈。
GPU 作为最早从事并行加速计算的处理器,相比 CPU 速度快, 同时比其他加速器芯片编程灵活简单。
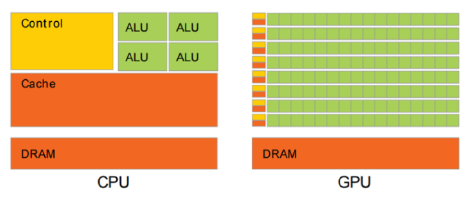
传统的 CPU 之所以不适合人工智能算法的执行,主要原因在于其计算指令遵循串行执行的方式,没能发挥出芯片的全部潜力。与之不同的是, GPU 具有高并行结构,在处理图形数据和复杂算法方面拥有比 CPU 更高的效率。对比 GPU 和 CPU 在结构上的差异, CPU大部分面积为控制器和寄存器,而 GPU 拥有更ALU(逻辑运算单元)用于数据处理,这样的结构适合对密集型数据进行并行处理, CPU 与 GPU 的结构对比如图 所示。
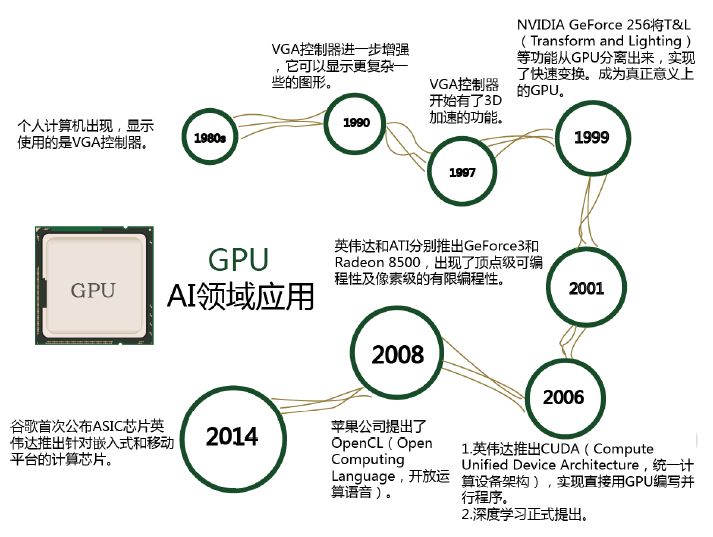
程序在 GPU系统上的运行速度相较于单核 CPU往往提升几十倍乃至上千倍。随着英伟达AMD等公司不断推进其对 GPU 大规模并行架构的支持,面向通用计算的 GPU(即GPGPU,通用计算图形处理器)已成为加速可并行应用程序的重要手段,GPU 的发展历程可分为 3 个阶段:
第一代GPU(1999年以前),部分功能从CPU分离 , 实现硬件加速 , 以GE(GEOMETRY ENGINE)为代表,只能起到 3D 图像处理的加速作用,不具有软件编程特性。
第二代 GPU(1999-2005 年), 实现进一步的硬件加速和有限的编程性。 1999年,英伟达发布了“专为执行复杂的数学和几何计算的” GeForce256 图像处理芯片,将更多的晶体管用作执行单元, 而不是像 CPU 那样用作复杂的控制单元和缓存,将(TRANSFORM AND LIGHTING) 等功能从 CPU 分离出来,实现了快速变换,这成为 GPU 真正出现的标志。之后几年, GPU 技术快速发展,运算速度迅速超过 CPU。 2001年英伟达和ATI 分别推出的GEFORCE3和RADEON 8500,图形硬件的流水线被定义为流处理器,出现了顶点级可编程性,同时像素级也具有有限的编程性,但 GPU 的整体编程性仍然比较有限。
2008年,苹果公司提出一个通用的并行计算编程平台 OPENCL(开放运算语言),与CUDA绑定在英伟达的显卡上不同,OPENCL 和具体的计算设备无关。
目前, GPU 已经发展到较为成熟的阶段。谷歌、 FACEBOOK、微软、 Twtter和百度等公司都在使用GPU 分析图片、视频和音频文件,以改进搜索和图像标签等应用功能。此外,很多汽车生产商也在使用GPU芯片发展无人驾驶。 不仅如此, GPU也被应用于VR/AR 相关的产业。
但是 GPU也有一定的局限性。 深度学习算法分为训练和推断两部分, GPU 平台在算法训练上非常高效。但在推断中对于单项输入进行处理的时候,并行计算的优势不能完全发挥出来。
FPGA 是在 PAL、 GAL、CPLD等可编程器件基础上进一步发展的产物。用户可以通过烧入 FPGA 配置文件来定义这些门电路以及存储器之间的连线。这种烧入不是一次性的,比如用户可以把 FPGA 配置成一个微控制器MCU,使用完毕后可以编辑配置文件把同一个FPGA 配置成一个音频编解码器。因此, 它既解决了定制电路灵活性的不足,又克服了原有可编程器件门电路数有限的缺点。
FPGA可同时进行数据并行和任务并行计算,在处理特定应用时有更加明显的效率提升。对于某个特定运算,通用 CPU可能需要多个时钟周期,而 FPGA 可以通过编程重组电路,直接生成专用电路,仅消耗少量甚至一次时钟周期就可完成运算。
此外,由于 FPGA的灵活性,很多使用通用处理器或 ASIC难以实现的底层硬件控制操作技术, 利用 FPGA 可以很方便的实现。这个特性为算法的功能实现和优化留出了更大空间。同时FPGA 一次性成本(光刻掩模制作成本)远低于ASIC,在芯片需求还未成规模、深度学习算法暂未稳定, 需要不断迭代改进的情况下,利用 FPGA 芯片具备可重构的特性来实现半定制的人工智能芯片是最佳选择之一。
功耗方面,从体系结构而言, FPGA 也具有天生的优势。传统的冯氏结构中,执行单元(如 CPU 核)执行任意指令,都需要有指令存储器、译码器、各种指令的运算器及分支跳转处理逻辑参与运行, 而FPGA每个逻辑单元的功能在重编程(即烧入)时就已经确定,不需要指令,无需共享内存,从而可以极大的降低单位执行的功耗,提高整体的能耗比。
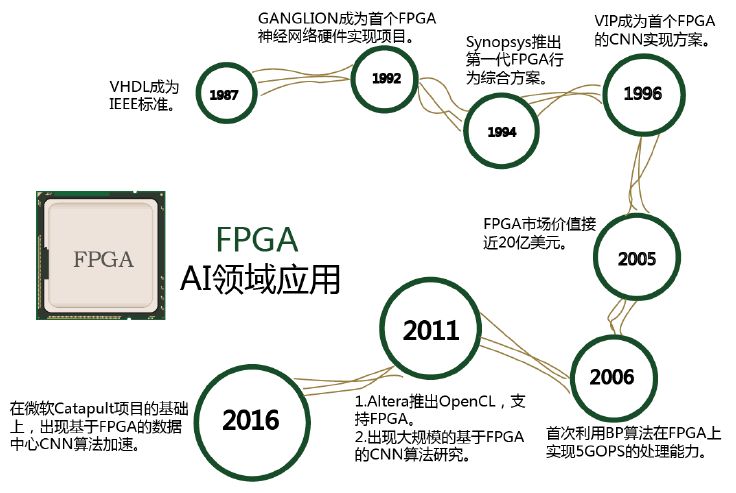
由于 FPGA 具备灵活快速的特点, 因此在众多领域都有替代ASIC 的趋势。 FPGA 在人工智能领域的应用如图所示。
目前以深度学习为代表的人工智能计算需求,主要采用GPU、FPGA等已有的适合并行计算的通用芯片来实现加速。在产业应用没有大规模兴起之时,使用这类已有的通用芯片可以避免专门研发定制芯片(ASIC)的高投入和高风险。但是,由于这类通用芯片设计初衷并非专门针对深度学习,因而天然存在性能、 功耗等方面的局限性。随着人工智能应用规模的扩大,这类问题日益突显。
GPU作为图像处理器, 设计初衷是为了应对图像处理中的大规模并行计算。因此,在应用于深度学习算法时,有三个方面的局限性:
第一:应用过程中无法充分发挥并行计算优势。 深度学习包含训练和推断两个计算环节, GPU 在深度学习算法训练上非常高效, 但对于单一输入进行推断的场合, 并行度的优势不能完全发挥。
第二:无法灵活配置硬件结构。 GPU 采用 SIMT 计算模式, 硬件结构相对固定。 目前深度学习算法还未完全稳定,若深度学习算法发生大的变化, GPU 无法像 FPGA 一样可以灵活的配制硬件结构。
尽管 FPGA 倍受看好,甚至新一代百度大脑也是基于 FPGA 平台研发,但其毕竟不是专门为了适用深度学习算法而研发,实际应用中也存在诸多局限:
第一:基本单元的计算能力有限。为了实现可重构特性, FPGA 内部有大量极细粒度的基本单元,但是每个单元的计算能力(主要依靠 LUT 查找表)都远远低于 CPU 和 GPU 中的 ALU 模块。
第二:计算资源占比相对较低。 为实现可重构特性, FPGA 内部大量资源被用于可配置的片上路由与连线。
第四,:FPGA 价格较为昂贵。在规模放量的情况下单块 FPGA 的成本要远高于专用定制芯片。
因此,随着人工智能算法和应用技术的日益发展,以及人工智能专用芯片 ASIC产业环境的逐渐成熟, 全定制化人工智能 ASIC也逐步体现出自身的优势,从事此类芯片研发与应用的国内外比较有代表性的公司如图所示。
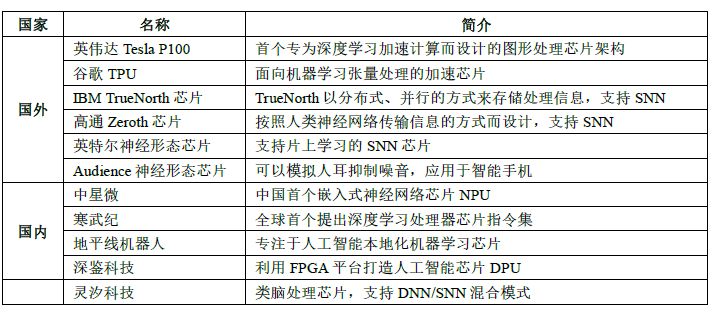
深度学习算法稳定后,AI芯片可采用ASIC设计方法进行全定制, 使性能、功耗和面积等指标面向深度学习算法做到最优。
类脑芯片不采用经典的冯·诺依曼架构, 而是基于神经形态架构设计,以IBM Truenorth为代表。 IBM 研究人员将存储单元作为突触、计算单元作为神经元、传输单元作为轴突搭建了神经芯片的原型。
目前, Truenorth用三星28nm功耗工艺技术,由 54亿个晶体管组成的芯片构成的片上网络有4096个神经突触核心,实时作业功耗仅为70mW。由于神经突触要求权重可变且要有记忆功能, IBM采用与CMOS工艺兼容的相变非易失存储器(PCM)的技术实验性的实现了新型突触,加快了商业化进程。
有外媒报道称,IBM人工智能和量子计算副总裁Dario Gil以及IBM前研究员Chad Riget....
据了解,谷歌正在计划建立一个机器学习型的自动化模式,并且对于企业开发者们来说可以利用这项技术去构建和....
全球领先的技术解决方案提供商安富利亚洲和AI软件领域的创新企业Mipsology宣布,安富利将向其亚....
以5G+AI技术为主导的高帧频、超高清、宽动态范围的4K、8K安防监控解决方案以及相关应用场景将成为....
基于头盔显示器对便携性的要求,要实现微型化和低功耗,将彩色时序控制器设计为单片的ASIC是较好的解决....
作为基础设施的“奠基者”,数据中心一直在底层默默无闻。但在数据化日益普及的今日,无论通信技术如何升级....
Aiva平台允许患者通过口头命令告诉设备他们需要什么,然后将请求发送给适当的护理人员。如果没有及时回....
这些诊所提供功能强大的虚拟和现场医疗专业人员,并利用AI和增强现实(AR)指导患者进行整个诊断过程,....
他在奥尔兰举行的医疗信息与管理系统协会(HIMSS)会议上告诉STAT:“我很高兴看到2018年尘埃....
谷歌利用人工智能来改善Duo通线G通信技术发展,网络通话越来越盛行。但是网络不稳定是常态,所以通话中我们时不时可能会....
根据Crunchbase提供的信息,该公司的A轮融资由Dream Incubator和Beenext....
近年来,电能质量日益引起人们的重视,如何有效的监测和分析电能质量参数逐渐成为电力企业和用户共同关心的....
“许多来我诊所的患者不需要手术,或者他们的病情不在我的专业范围内,因此AI系统要求患者上传详细信息并....
尽管最初为AlexNet图像和内核大小配置了MLP_Conv2D设计,但是2D卷积是一个通用过程,因....
FPGA的仿真与调试在FPGA开发过程中起着至关重要的作用,也占用了FPGA开发的大部分时间。所以适当减少或简化FPGA...
把握DCM、PLL、PMCD和MMCM知识是稳健可靠的时钟设计策略的基础。赛灵思在其FPGA中提供了丰富的时钟资源,大多...
仅在10年前,致力于他们希望开启神经形态计算新领域的科学家只能梦想使用一种称为忆阻器的微型工具,该工....
本届领航者峰会,新华三全新发布了“AI in ALL”的智能战略。根据新华三首席执行官于英涛介绍,“....
物联网技术的崛起为传统医疗带来改革巨浪,打破了医院的围墙,让医疗服务可以更深入触及到各个角落,缩短医....
此次收购为eDreams ODIGEO提供了重要的,创新的AI驱动技术和领先的酒店领域专业知识,这将....
能够提供导购服务的智能AI机器人,无需顾客亲自试穿的VR电子试衣镜,超高清的商场活动5G直播……近期....
首先,有关深度学习有效性的实验室证据并不像看起来那样可靠。当使用AI的机器胜过人类的机器时,正面的结....
找了很久只有创龙的有一款28377+fpga的,但是只能核心板和底板一起购买才能使用,价格实在太贵了,各位大哥还知道哪里有卖的吗,...
“拥有道德和可信赖的AI框架至关重要,因为这将作为创建可信赖的AI项目的指导,但最重要的是,它将在....
本文为明德扬原创及录用文章,转载请注明出处! 一、 什么是组合逻辑电路? 在数字电路中,根据逻辑功能的不同...
近日,泰尔终端实验室发布了“AI伪造人脸鉴别平台”,基于单帧和多帧的方法,利用人脸生物特征、抖动精度....
本文为明德扬原创文章,转载请注明出处! MDY有一条非常重要的看波形技巧,即“时钟上升沿前看条件”的技巧,...
至简案例系列:密码锁作者:造就狂野青春本文为明德扬原创及录用文章,转载请注明出处! 一、总体设计 1.概述 ...
基于FPGA的密码锁设计 1项目背景概述 随着生活质量的不断提高,加强家庭防盗安全变得非常重要...
近日,泰尔终端实验室发布了“AI伪造人脸鉴别平台”,基于单帧和多帧的方法,利用人脸生物特征、抖动精度....
从无人驾驶汽车的上路,到无人机的自主巡检,再到AI合成主播上岗......人工智能正在渗透进我们的日....
为了提高人们对人工智能的信任度,相关系统必须可靠、公正、负责。必须让公众确信人工智能技术是安全的,人....
人工智能创新应用先导区,既是发展时期产业的领头羊,也要做特殊时期抗疫前线的先锋队,“养兵千日”的创新....
人工智能要融入“新基建”,必须满足作为基础设施的刚性共需、强外部性等基本属性,并不断着力于自身技术能....
自适应和智能计算的全球领先企业赛灵思公司(Xilinx, Inc.,(NASDAQ: XLNX))今....
智慧监狱中的这些智慧元素包括智慧办公系统、智慧改造系统(智慧安防系统、智慧教育矫正系统、阳光执法系统....
J-link Pro+ V4.5 版:市面上能买到的最新版本!老鸟必备。 168MHz 的 407....
诺贝尔化学奖得主吉野彰(Akira Yoshino)在大阪举行了记者招待会。他指出,2025年国际博....
系统采用 ARM 为主控制芯片,完成对射频识别芯片的控制、信息采集、数据传输以及对医疗器械的控制功能....
Hitachi Vantara数字基础架构总裁Brian Householder表示:“几十年以来,....
紫光同创已经联合ALINX在去年推出了PGL22G开发板,采用核心板加扩展板的模式。扩展板上,设计了....
谷歌于2017年更改了算法,由扎克伯格旧金山总医院医学博士Elaine Khoong和UCSF领导....
该工具将生物技术与机器学习相结合,是一个分为两部分的过程的一部分。使用纸质试纸,用户将每天测试他们的....
澳大利亚皇家放射学院和新西兰放射医学学院(RANZCR)在最近公布了有关机器学习和AI在医学中的新兴....
多亏了Thunderbolt 3端口,它才支持Razer的Core X eGPU。这使超级本可以在双....
数世咨询创始人李少鹏表示:“网络安全产业爆发的一个重要前提是理念上的转变。从事件驱动,到威胁驱动,再....
随着人工智能、机器学习等应用场景快速发展演进,对芯片的算力、安全性等性能也提出了更高的诉求。
游戏玩家在游戏设备前徒手对空做着各种动作,轻松扮演各种虚拟世界的游戏角色;各色机器人在各种场景中自主....
Astera Labs是一家即将迎来迅速发展的公司,它正在逐步提高其连接解决方案的产量,以满足产业界....
人工智能(AI)的科学和艺术已经给不同的行业带来了重大的变革。旅游业也不例外,其中很多的商业垂直领域....
具体而言,该演示在Abaco的SOSA对准SBC3511上进行,并可以通过Abaco的GPGPU板(....
Gottlieb说:“我们正在探索一个框架,该框架将允许对来自现实世界学习和适应的算法进行修改,同时....
本文档的主要内容详细介绍的是FPGA入门教程之HELLO FPGA软件工具篇PDF电子书免费下载。
TMP411 ±1°C Programmable Remote/Local Digital Out Temperature Sensor
TMP411设备是一个带有内置本地温度传感器的远程温度传感器监视器。远程温度传感器,二极管连接的晶体管通常是低成本,NPN或PNP型晶体管或二极管,是微控制器,微处理器或FPGA的组成部分。 远程精度为1 C适用于多个设备制造商,无需校准。双线串行接口接受SMBus写字节,读字节,发送字节和接收字节命令,以设置报警阈值和读取温度数据。 TMP411器件中包含的功能包括:串联电阻取消,可编程非理想因子,可编程分辨率,可编程阈值限制,用户定义的偏移寄存器,用于最大精度,最小和最大温度监视器,宽远程温度测量范围(高达150C),二极管故障检测和温度警报功能。 TMP411器件采用VSSOP-8和SOIC-8封装。 特性 1C远程二极管传感器 1C本地温度传感器 可编程非理想因素 串联电阻取消 警报功能 系统校准的偏移寄存器 与ADT7461和ADM1032兼容的引脚和寄存器 可编程分辨率:9至12位 可编程阈值限...
TMP468器件是一款使用双线 C兼容接口的多区域高精度低功耗温度传感器。除了本地温度外,还可以同时监控多达八个连接远程二极管的温度区域。聚合系统中的温度测量可通过缩小保护频带提升性能,并且可以降低电路板复杂程度。典型用例为监测服务器和电信设备等复杂系统中不同处理器(如MCU,GPU和FPGA)的温度。该器件将诸如串联电阻抵消,可编程非理想性因子,可编程偏移和可编程温度限值等高级特性完美结合,提供了一套精度和抗扰度更高且稳健耐用的温度监控解决方案。 八个远程通道(以及本地通道)均可独立编程,设定两个在测量位置的相应温度超出对应值时触发的阈值。此外,还可通过可编程迟滞设置避免阈值持续切换。 TMP468器件可提供高测量精度(0.75C)和测量分辨率(0.0 625C)。该器件还支持低电压轨(1.7V至3.6V)和通用双线制接口,采用高空间利用率的小型封装(3mm×3mm或1.6mm×1.6mm),可在计算系统中轻松集成。远程结支持-55C至+ 150C的温度范围。 特性 8通道远程二极管温度传感器精度:0.75&...
