“算法”源自波斯学者al-Khwarizmi名字的拉丁化。他于9世纪在巴格达撰写了著作《印度数字计算》一书,该书向西方引入了印度教的数字,以及相应的计算数字的新方法,即算法。

中世纪拉丁语“algorismus”指的是用印度数字进行四个基本数学运算——加法,减法,乘法和除法的程序和捷径。后来,术语“算法”被人们用作表示任何逐步的逻辑过程,并成为计算逻辑的核心。
算法就是计算或者解决问题的步骤。想用计算机解决特定的问题,就要遵循相应的算法。这里所说的特定问题多种多样,比如:“将随意排列的数字按从小到大的顺序重新排列”、“寻找出发点到目的地的最短路径”等等。
现在算法已经广泛应用到了我们生活当中,在浏览淘宝的时候,推荐的商品,就应用到了协同推荐算法,我和老王都买了a, b这两个商品,并且老王还买了c。那么,有比较大的概率我也会喜欢c商品。推荐算法认为,当你喜欢一个物品时,你会倾向于也喜欢同类型的其他物品。于是,当用户翻牌了其中一首歌,与它相似的那一堆歌曲很快就会亮起来然后被放进推荐中。
算法时代已经到来,算法带来的变化就发生在我们身边:滴滴打车使用算法来连接司机和乘客;美团用算法连接了商家和客户和物流,并通过规划最优路径将食物直接“投递”到手中。
智能算法正在颠覆整个行业。但是,这种改变才刚刚开始,未来十年将有可能看到所有行业都受到算法的影响。算法可以更快做出更明智的决策,并且降低风险,这就是算法的意义。
解决不同的问题需要用到不同的算法,或者是几种算法配合使用。熟悉并了解各类算法,对AI产品经理在设计产品的时候可以起到辅助决策。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。常见的决策树算法有C4.5、ID3和CART。
决策树的目的是用于分类预测,即各个节点需要选取输入样本的特征,进行规则判定,最终决定样本归属到哪一棵子树。决策树是一种简单常用的分类器,通过训练好的决策树可以实现对未知的数据进行高效分类。
随机森林是最流行也最强大的机器学习算法之一,它是一种集成机器学习算法。随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,上面我们讲过啥是决策树,而它的本质属于机器学习的一大分支——集成学习方法。
随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,这样的比喻还是很贴切的,其实这也是随机森林的主要思想——集成思想的体现。
Logistic 回归是机器学习从统计学领域借鉴过来的另一种技术。其主要思想是:根据现有数据对分类边界线(Decision Boundary)建立回归公式,以此进行分类,它是二分类问题的首选方法。
像线性回归一样,Logistic 回归的目的也是找到每个输入变量的权重系数值。但不同的是,Logistic 回归的输出预测结果是通过一个叫作「logistic 函数」的非线性函数变换而来的。
K 最近邻(KNN)算法是非常简单而有效的,KNN 的模型表示就是整个训练数据集,这很简单吧?
对新数据点的预测结果是通过在整个训练集上搜索与该数据点最相似的 K 个实例(近邻),并且总结这 K 个实例的输出变量而得出的。对于回归问题来说,预测结果可能就是输出变量的均值;而对于分类问题来说,预测结果可能是众数(或最常见的)的类的值。
最近邻算法的思想很简单,“距离”相近的事物总会具有更多的共性。例如:预测一个人的饮食风格只是根据与他相近的人来预测的,而并没有说明这个人的年龄、收入是如何影响他的饮食风格的。
在我们生活的这个世界中到处都是被排序过的。站队的时候会按照身高排序,考试的名次需要按照分数排序,如何快速高效排序,有多种算法,经典的排序算法有插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序。其中插入排序是一种最简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
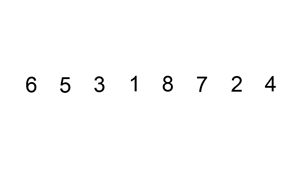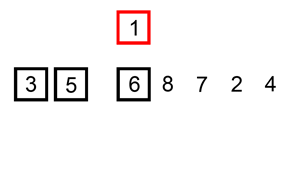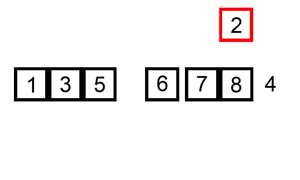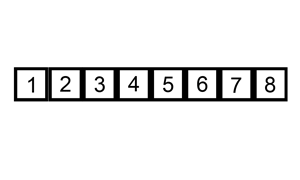
查找是在大量的信息中寻找一个特定的信息元素,在计算机应用中,查找是常用的基本运算,例如编译程序中符号表的查找。
最为经典的算法有顺序查找算法、二分查找算法、插值查找算法、斐波那契查找算法、树表查找算法、分块查找算法、哈希查找等。
要了解哈希查找就要先了解哈希函数,要了解哈希函数就要先了解哈希表,哈希表,亦称散列表,是通过函数映射的方式将关键字和存储位置建立联系,进而实现快速查找。哈希函数的规则是通过某种转换关系,使关键字适度的分散到指定大小的的顺序结构中,越分散,则以后查找的时间复杂度越小,空间复杂度越高。
哈希查找的思路很简单,如果所有的键都是整数,那么就可以使用一个简单的无序数组来实现:将键作为索引,值即为其对应的值,这样就可以快速访问任意键的值。这是对于简单的键的情况,我们将其扩展到可以处理更加复杂的类型的键。现在的以图搜图的关键算法就是应用了哈希查找算法。
所谓贪心算法是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的仅是在某种意义上的局部最优解。
贪心算法的基本思路是首先建立数学模型来描述问题,把求解的问题分成若干个子问题。然后对每一子问题求解,得到子问题的局部最优解,最后把子问题的解局部最优解合成原来解问题的一个解。因为用贪心算法只能通过解局部最优解的策略来达到全局最优解,因此,一定要注意判断问题是否适合采用贪心算法策略,找到的解是否一定是问题的最优解。
动态规划(Dynamic Programming)是一种把原问题分解为相对简单的子问题以求解的方法,为了避免多次解决重复的子问题,子问题的结果都被保存,直到整个问题得以解决。
图论起源于一个著名的数学问题——柯尼斯堡(Konigsberg)问题,即七桥问题。1738 年,瑞典数学家Eular 解决了这个问题,他也成为了图论的创始人。
如今图论是数学的一个分支,它以图为研究对象。图论中的图是由若干给定的点及连接两点的线所构成的图形,这种图形通常用来描述某些事物之间的某种特定关系,用点代表事物,用连接两点的线表示相应两个事物间具有这种关系。图论算法是用来求解实际问题的一种方法,在数学建模的求解过程中经常应用。
逻辑回归是一种用于解决监督学习问题的学习算法,进行逻辑回归的目的,是使训练数据的标签值与预测出来的值之间的误差最小化。逻辑回归广泛应用于机器学习中,其中清洗脏数据最为广泛,在数据行业有一个笑线%的工作是数据清洗,另外20%是抱怨数据清洗。
逻辑回归具有实现简单,分类时计算量非常小,速度很快,存储资源低;便利的观测样本概率分数;计算代价不高,易于理解和实现等优点。
预测建模主要关注的是在牺牲可解释性的情况下,尽可能最小化模型误差或做出最准确的预测。我们将借鉴、重用来自许多其它领域的算法(包括统计学)来实现这些目标。
支持向量机(support vector machine)是一种分类算法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。
通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
人工神经网络是在现代神经科学的基础上提出和发展起来的一种旨在反映人脑结构及功能的抽象数学模型。它具有人脑功能基本特性:学习、记忆和归纳。人工神经网络是机器学习的一个庞大的分支,有几百种不同的算法。
k-means算法是非监督聚类最常用的一种方法,因其算法简单和很好的适用于大样本数据,广泛应用于不同领域,K-means聚类算法用来查找那些包含没有明确标记数据的组。这可以用于确定商业假设,存在什么类型的分组或为复杂的数据集确定未知组。一旦该算法已运行并定义分组,任何新数据可以很容易地分配到正确的组。
协同过滤,从字面上理解,包括协同和过滤两个操作。所谓协同就是利用群体的行为来做决策(推荐),生物上有协同进化的说法,通过协同的作用,让群体逐步进化到更佳的状态。
对于推荐系统来说,通过用户的持续协同作用,最终给用户的推荐会越来越准。而过滤,就是从可行的决策(推荐)方案(标的物)中将用户喜欢的方案(标的物)找(过滤)出来。
具体来说,协同过滤的思路是通过群体的行为来找到某种相似性(用户之间的相似性或者标的物之间的相似性),通过该相似性来为用户做决策和推荐。只不过协同过滤算法依赖用户的行为来为用户做推荐,如果用户行为少(比如新上线的产品或者用户规模不大的产品),这时就很难发挥协同过滤算法的优势和价值,甚至根本无法为用户做推荐。这时可以采用基于内容的推荐算法作为补充。
分层聚类,又称层次聚类、系统聚类,顾名思义是指聚类过程是按照一定层次进行的。比如当前有8个裁判对于300个选手进行打分,试图想对8个裁判进行聚类,以挖掘出裁判的打分偏好风格类别情况,此时则需要进行分层聚类。
DBSCAN 是一种基于密度的聚类算法,它类似于均值漂移,但具有一些显著的优点。其主要原理是只要邻近区域的密度(对象或数据点的数目)超过某个阈值,就继续聚类,该算法擅于解决不规则形状的聚类问题,广泛应用于空间信息处理,SGC,GCHL,DBSCAN算法、OPTICS算法、DENCLUE算法。
关于高斯分布模型的基本理论。GMM的归纳偏好为数据服从 Gaussian Distribution ,换句话说,数据可以看作是从数个 Gaussian Distribution 中生成出来的。所以在这个假设前提下,再反推已知一堆数据,必须还得知道这些数据有几个部分(类)组成吧,知道这个基本参数,才能正确的进行聚类吧。
EM算法常用在有隐变量的参数的求解,比如混合高斯模型(Gaussian Mixture Model)。EM算法是可以收敛的,但是可能会陷于局部最小值,所以我们一般需要多次去初始值,选择最后的那个作为我们的结果。
AdaBoost 是第一个为二分类问题开发的真正成功的 Boosting 算法。它是人们入门理解 Boosting 的最佳起点。当下的 Boosting 方法建立在 AdaBoost 基础之上,最著名的就是随机梯度提升机。
Boosting 是一种试图利用大量弱分类器创建一个强分类器的集成技术。要实现 Boosting 方法,首先你需要利用训练数据构建一个模型,然后创建第二个模型(它企图修正第一个模型的误差)。直到最后模型能够对训练集进行完美地预测或加入的模型数量已达上限,我们才停止加入新的模型。
消耗算力小:简单的算法对人来说易于理解,也容易被写成程序,而在运行过程中不需要耗费太多空间资源的算法,就十分适用于内存小的计算机。
时效性强:对于实时响应的程序我们一般来说我们最为重视的是算法的运行时间,即时效,也是从输入数据到输出结果这个过程所花费的时间。
在一般人眼中,算法是一种深奥枯燥难以理解的东西。但是在AI产品经理眼中,算法是一把把好用的工具,可以帮助产品经理搭建出一个个完美的杰作。对算法的了解程度不必太深,比较产品经理不是码代码的,但是了解算法的原理及应用场景,必不可少。
作者:老张,宜信集团保险事业部智能保险产品负责人,运营军师联盟创始人之一,《运营实战手册》作者之一。
人人都是产品经理(是以产品经理、运营为核心的学习、交流、分享平台,集媒体、培训、社群为一体,全方位服务产品人和运营人,成立9年举办在线+期,线+场,产品经理大会、运营大会20+场,覆盖北上广深杭成都等15个城市,在行业有较高的影响力和知名度。平台聚集了众多BAT美团京东滴滴360小米网易等知名互联网公司产品总监和运营总监,他们在这里与你一起成长。
