,主要用于管理与组织Hadoop工作流。Oozie的工作流必须是一个有向无环图,实际上Oozie就相当于Hadoop的一个客户端,当用户需要执行多个关联的MR任务时,只需要将MR执行顺序写入workflow.xml,然后使用Oozie提交本次任务,Oozie会托管此任务流。
现实业务中处理数据时不可能只包含一个MR操作,一般都是多个MR,并且中间还可能包含多个Java或HDFS,甚至是shell的操作,利用Oozie可以完成这些任务。
实际上Oozie不是仅用来配置多个MR工作流的,它可以是各种程序夹杂在一起的工作流,比如执行一个MR1后,接着执行一个java脚本,再执行一个shell脚本,接着是Hive脚本,然后又是Pig脚本,最后又执行了一个MR2,使用Oozie可以轻松完成这种多样的工作流。使用Oozie时,若前一个任务执行失败,后一个任务将不会被调度。
时间(比如说。每天晚上10点到凌晨2点之间,没半个小时运行一次。比如说,每周五的晚上8点触发一次)
2,Oozie工作流定义,同Jboss jBPM提供的jPDL一样,提供了类似的流程定义语言hPDL,通过XML文件格式来实现流程的定义。对于工作流系统,一般会有很多不同功能的节点,比如分支,并发,汇合等等。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。 如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!
这个东东,经别人说才知道,所以感觉也是比较惭愧。毕竟正在做的项目DIP-DATA-ANALYZE与这个有些共同处,就是提供类似工作流的机制更好的调度任务。不过
首先本人以前还真不知道Oozie这个东东,经别人说才知道,所以感觉也是比较惭愧。毕竟正在做的项目DIP-DATA-ANALYZE与这个有些共同处,就是提供类似工作流的机制更好的调度任务。不过Oozie支持的更多,支持了pig,直接mr,streaming。我们目前是基于hive的,当然也可以支持streaming,mr,不过目前还没有。
另外一个不同是Oozie使用自定义的xml语言hPDL来定义工作流。工作如何进行全部在配置文件中定义。而DIP-DATA-ANALYZE完全界面化,通过选择原任务来指定这个依赖关系。易用性方面个人觉得我们的使用起来更加方便些。当然一些工作流设计实现上Oozie更加完善。
Oozie是一种Java Web应用程序,它运行在Java servlet容器——即Tomcat——中,并使用数据库来存储以下内容:
Oozie工作流是放置在控制依赖DAG(有向无环图 Direct Acyclic Graph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。我们会使用hPDL(一种XML流程定义语言)来描述这个图。
hPDL是一种很简洁的语言,只会使用少数流程控制和动作节点。控制节点会定义执行的流程,并包含工作流的起点和终点(start、end和fail节点)以及控制工作流执行路径的机制(decision、fork和join节点)。动作节点是一些机制,通过它们工作流会触发执行计算或者处理任务。Oozie为以下类型的动作提供支持: Hadoop map-reduce、Hadoop文件系统、Pig、Java和Oozie的子工作流(SSH动作已经从Oozie schema 0.2之后的版本中移除了)。
所有由动作节点触发的计算和处理任务都不在Oozie之中——它们是由Hadoop的Map/Reduce框架执行的。这种方法让Oozie可以支持现存的Hadoop用于负载平衡、灾难恢复的机制。这些任务主要是异步执行的(只有文件系统动作例外,它是同步处理的)。这意味着对于大多数工作流动作触发的计算或处理任务的类型来说,在工作流操作转换到工作流的下一个节点之前都需要等待,直到计算或处理任务结束了之后才能够继续。Oozie可以通过两种不同的方式来检测计算或处理任务是否完成,也就是回调和轮询。当Oozie启动了计算或处理任务的时候,它会为任务提供唯一的回调URL,然后任务会在完成的时候发送通知给特定的URL。在任务无法触发回调URL的情况下(可能是因为任何原因,比方说网络闪断),或者当任务的类型无法在完成时触发回调URL的时候,Oozie有一种机制,可以对计算或处理任务进行轮询,从而保证能够完成任务。
Oozie工作流可以参数化(在工作流定义中使用像${inputDir}之类的变量)。在提交工作流操作的时候,我们必须提供参数值。如果经过合适地参数化(比方说,使用不同的输出目录),那么多个同样的工作流操作可以并发。
一些工作流是根据需要触发的,但是大多数情况下,我们有必要基于一定的时间段和(或)数据可用性和(或)外部事件来运行它们。Oozie协调系统(Coordinator system)让用户可以基于这些参数来定义工作流执行计划。Oozie协调程序让我们可以以谓词的方式对工作流执行触发器进行建模,那可以指向数据、事件和(或)外部事件。工作流作业会在谓词得到满足的时候启动。
经常我们还需要连接定时运行、但时间间隔不同的工作流操作。多个随后运行的工作流的输出会成为下一个工作流的输入。把这些工作流连接在一起,会让系统把它作为数据应用的管道来引用。Oozie协调程序支持创建这样的数据应用管道。

工作流控制可以通过decision\fork\join等几个节点完成。目前不支持环形工作流.
动作和决定可以和job的属性、action的输出(例如计数等)、hdfs的文件信息(是否存在、大小等)一起参数化。这些参数可以使用${var}定义在工作流配置文件中。
工作流应用是一个包含了工作流定义(xml文件),所有必须的文件的目录,并执行所有的动作。这些必须文件包括jar文件(用来执行mr任务)、shell脚本(用来执行streaming mr 任务)、还有其他的比如本地库、pig脚本以及其他文件。
通过web控制台、命令行工具、webservice api、java api即可对系统和工作流任务进行监控。Oozie是一个事务系统,其已经内在支持了自动化和手动的重试机制。(这点DIP-DATA-ANALYZE有转发(自动第二次重试),jobtrace(手动重试)也可以支持).
如果任务失败了,工作流的任务就会略过之前完成的动作重新执行,并且工作流应用在重新运行前可以被修补(这里patched不确定是否这样表达).
是大数据四大协作框架之一——任务调度框架,另外三个分别为数据转换工具Sqoop,文件收集库框架Flume,大数据WEB工具Hue。 它能够提供对Hadoop MapReduce和Pig Jobs的任务调度与协调。
Oozie是大数据四大协作框架之一——任务调度框架,另外三个分别为数据转换工具Sqoop,文件收集库框架Flume,大数据WEB工具Hue。
Oozie工作流定义,同JBoss jBPM提供的jPDL一样,也提供了类似的流程定义语言hPDL,通过XML文件格式来实现流程的定义。对于工作流系统,一般都会有很多不同功能的节点,比如分支、并发、汇合等等。
Oozie定义了控制流节点(Control Flow Nodes)和动作节点(Action Nodes),其中控制流节点定义了流程的开始和结束,以及控制流程的执行路径(Execution Path),如decision、fork、join等;而动作节点包括Hadoop map-reduce、Hadoop文件系统、Pig、SSH、HTTP、eMail和Oozie子流程。
oozie本质就是一个作业协调工具(底层原理是通过将xml语言转换成mapreduce程序来做,但只是在集中map端做处理,避免shuffle的过程。)
Oozie的工作流必须是一个有向无环图,实际上Oozie就相当于Hadoop的一个客户端,当用户需要执行多个关联的MR任务时,只需要将MR执行顺序写入workflow.xml,然后使用Oozie提交本次任务,Oozie会托管此任务流。
Oozie是一种Java Web应用程序,它运行在Java servlet容器——即Tomcat——中,并使用数据库来存储以下内容:
Oozie工作流是放置在控制依赖DAG(有向无环图 Direct Acyclic Graph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。我们会使用hPDL(一种XML流程定义语言)来描述这个图。
hPDL是一种很简洁的语言,只会使用少数流程控制和动作节点。控制节点会定义执行的流程,并包含工作流的起点和终点(start、end和fail节点)以及控制工作流执行路径的机制(decision、fork和join节点)。动作节点是一些机制,通过它们工作流会触发执行计算或者处理任务。Oozie为以下类型的动作提供支持: Hadoop map-reduce、Hadoop文件系统、Pig、Java和Oozie的子工作流(SSH动作已经从Oozie schema 0.2之后的版本中移除了)。
所有由动作节点触发的计算和处理任务都不在Oozie之中——它们是由Hadoop的Map/Reduce框架执行的。这种方法让Oozie可以支持现存的Hadoop用于负载平衡、灾难恢复的机制。这些任务主要是异步执行的(只有文件系统动作例外,它是同步处理的)。这意味着对于大多数工作流动作触发的计算或处理任务的类型来说,在工作流操作转换到工作流的下一个节点之前都需要等待,直到计算或处理任务结束了之后才能够继续。Oozie可以通过两种不同的方式来检测计算或处理任务是否完成,也就是回调和轮询。当Oozie启动了计算或处理任务的时候,它会为任务提供唯一的回调URL,然后任务会在完成的时候发送通知给特定的URL。在任务无法触发回调URL的情况下(可能是因为任何原因,比方说网络闪断),或者当任务的类型无法在完成时触发回调URL的时候,Oozie有一种机制,可以对计算或处理任务进行轮询,从而保证能够完成任务。
Oozie工作流可以参数化(在工作流定义中使用像${inputDir}之类的变量)。在提交工作流操作的时候,我们必须提供参数值。如果经过合适地参数化(比方说,使用不同的输出目录),那么多个同样的工作流操作可以并发。
一些工作流是根据需要触发的,但是大多数情况下,我们有必要基于一定的时间段和(或)数据可用性和(或)外部事件来运行它们。Oozie协调系统(Coordinator system)让用户可以基于这些参数来定义工作流执行计划。Oozie协调程序让我们可以以谓词的方式对工作流执行触发器进行建模,那可以指向数据、事件和(或)外部事件。工作流作业会在谓词得到满足的时候启动。
经常我们还需要连接定时运行、但时间间隔不同的工作流操作。多个随后运行的工作流的输出会成为下一个工作流的输入。把这些工作流连接在一起,会让系统把它作为数据应用的管道来引用。Oozie协调程序支持创建这样的数据应用管道。
写在前面: 博主是一名软件工程系大数据应用开发专业大二的学生,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白,写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和...
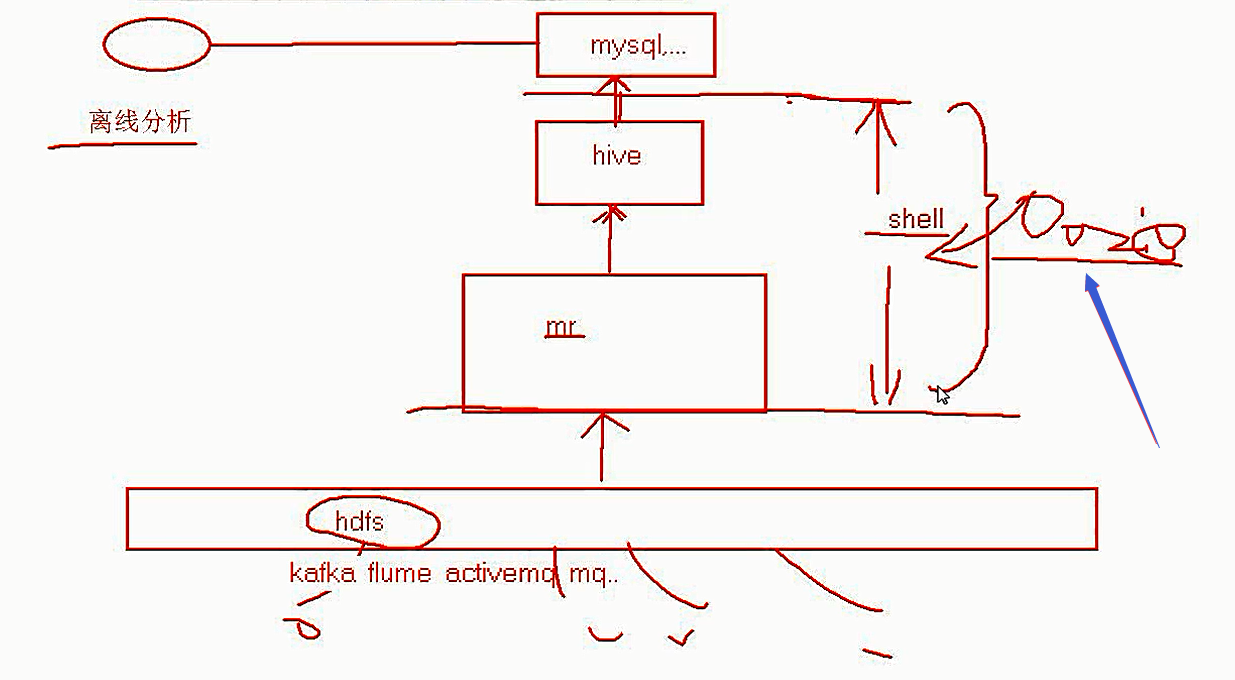
? 在数据业务场景,对于数据的处理往往是分阶段处理,而不同的阶段可能采用了不同的技术框架去完成这个业务需求,且可能在不同的阶段要干不同的事。 炒饭(锅) à 吃饭(碗) à 筷子(动手) 要吃饭...
絮叨两句: 博主是一名软件工程系的在校生,利用博客记录自己所学的知识,也希望能帮助到正在学习的同学们 ...
是运行在hadoop平台上的一种工作流调度引擎它可以用来调度与管理hadoop任务,如,MapReduc.
协调器促进了相互依赖的重复工作之间的协调,您可以使用预定的时间或数据可用性来触发 Apache
是什么? data-report-click={spm:3001.4431,dest:的
是什么?} data-report-query=spm=3001.4431
是什么? data-report-click={spm:3001.4431,dest:的
